Thực Trạng Triển Khai Các Dự Án Bản Sao Kỹ Thuật Số Hiện Nay
Trong làn sóng Cách mạng Công nghiệp 4.0, Digital Twin (Bản sao Kỹ thuật số) được xem là công nghệ lõi giúp doanh nghiệp giám sát, dự báo và tối ưu hóa quy trình. Từ các mô hình 3D trực quan đến tham vọng về thành phố thông minh, Digital Twin hiện diện trong nhiều chiến lược chuyển đổi số. Tuy nhiên, các báo cáo thực tế chỉ ra rằng không ít dự án Digital Twin chưa đạt được hiệu quả ROI (Return on Investment) như kỳ vọng, thường gặp khó khăn trong giai đoạn triển khai thực tế.
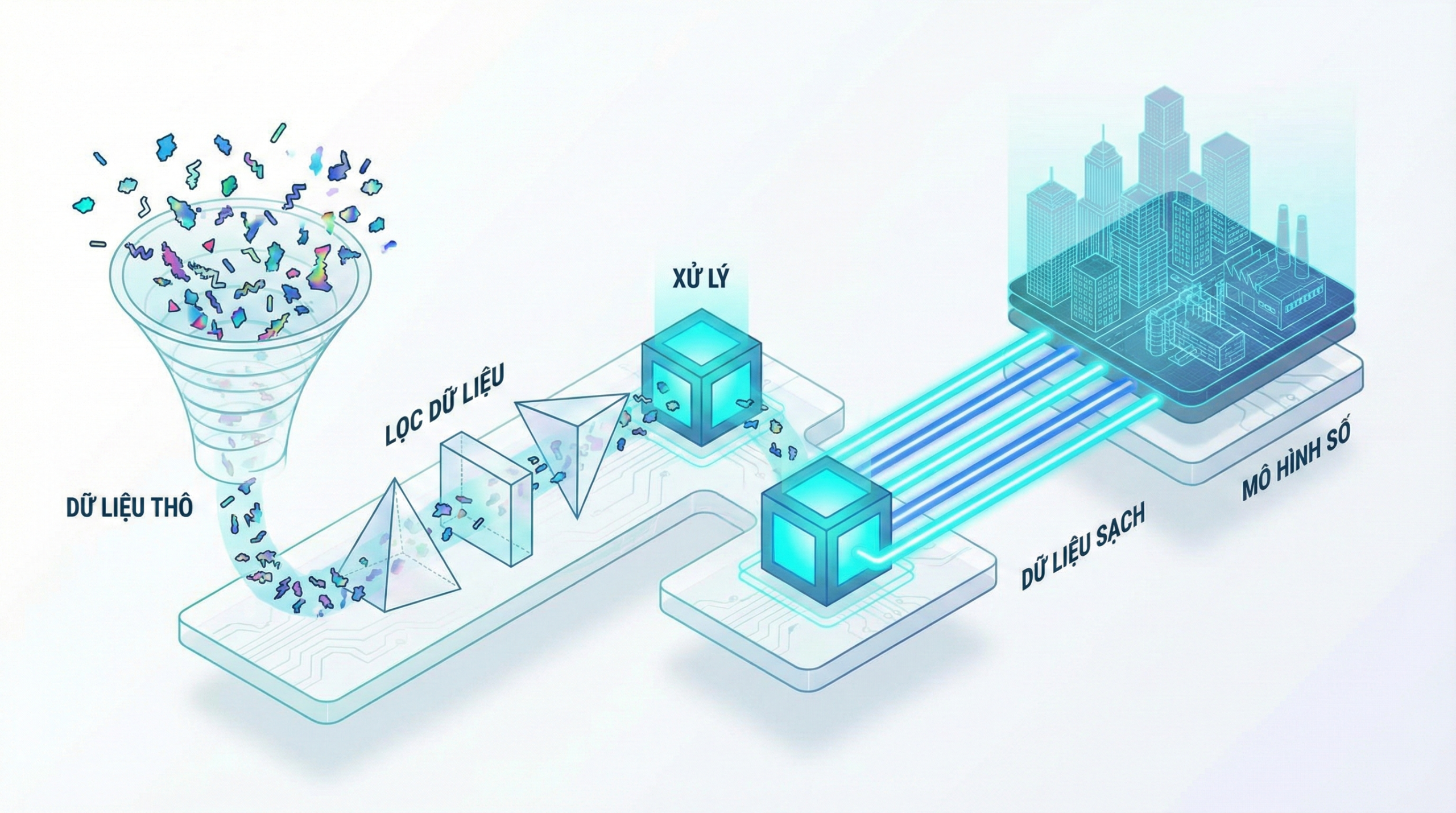
Nguyên nhân cốt lõi thường không nằm ở chất lượng cảm biến IoT hay thuật toán AI, mà nằm ở khâu trung gian quan trọng nhưng thường bị xem nhẹ: Quy trình Xử lý Dữ liệu (Data Processing) – nơi được ví là “Vùng Hỗn Mang” (The Messy Middle).
Nếu quan sát sơ đồ hệ sinh thái Digital Twin, chúng ta dễ bị thu hút bởi Không gian Vật lý (Physical Space) hoặc Không gian Ảo (Virtual Space) với các mô hình đồ họa bắt mắt. Tuy nhiên, chính cột Xử lý Dữ liệu (Data Processing) mới là yếu tố quyết định sự sống còn của hệ thống. Thiếu khả năng tiền xử lý (Preprocessing) và hợp nhất dữ liệu (Data Fusion) chuẩn xác, Digital Twin sẽ chỉ dừng lại ở mức độ một mô hình mô phỏng thiếu sức sống.
Báo cáo này sẽ phân tích sâu “Vùng Hỗn Mang” này dưới góc độ kỹ thuật (Kalman Filter, Sensor Drift) và cung cấp chiến lược nội dung để chuyển hóa các kiến thức này thành bài viết chuyên ngành chuẩn SEO, phù hợp với thị trường Việt Nam.
Kiến Trúc Hệ Sinh Thái & Vai Trò Cốt Lõi Của Dữ Liệu
Bản Chất Của Digital Twin: Dòng Chảy Dữ Liệu Hai Chiều
Một nhận định sai lầm phổ biến là đánh đồng Digital Twin với bản vẽ 3D/CAD tĩnh. Theo định nghĩa chuẩn, Digital Twin đòi hỏi dòng chảy dữ liệu hai chiều (bi-directional) tự động giữa thực thể vật lý và bản sao ảo. Nếu dữ liệu chỉ đi một chiều, đó chỉ là “Bóng Kỹ thuật số” (Digital Shadow). Khả năng thích ứng thời gian thực chính là sự khác biệt lớn nhất.
Phân Tích Cấu Trúc Hệ Thống (System Anatomy)
Hệ sinh thái Digital Twin được cấu thành từ ba trụ cột chính:
| Thành phần | Chức năng cốt lõi | Yếu tố cấu thành (Sub-components) |
| Không gian Vật lý (Physical Space) | Nguồn phát dữ liệu, nơi vận hành thực tế. | – Đối tượng (Máy móc, Hạ tầng). – Thuộc tính (Nhiệt, áp suất). – Tài nguyên (Cảm biến, Actuators). |
| Không gian Ảo (Virtual Space) | Bộ não phân tích, mô phỏng & ra quyết định. | – Mô hình Vật lý (Physics-based): Hình học, Động lực học. – Mô hình Dữ liệu (Data-driven): AI, Machine Learning. |
| Xử lý Dữ liệu (Data Processing) | Hệ thống kết nối, đảm bảo tính toàn vẹn dữ liệu. | – Tiền xử lý (Preprocessing): Lọc nhiễu, làm sạch. – Hợp nhất (Fusion): Kết hợp quá khứ, hiện tại, ảo. – Đồng bộ hóa & Trực quan hóa. |
Sự phân tách này cho thấy: Đầu tư vào phần cứng (Cột 1) hay phần mềm (Cột 2) sẽ lãng phí nếu “đường ống dẫn” (Cột 3) bị tắc nghẽn bởi dữ liệu kém chất lượng.

Tiền Xử Lý Dữ Liệu (Preprocessing) – Nền Tảng Của Độ Chính Xác
Thách Thức Tại Biên (The Edge Reality)
Triển khai IoT trong môi trường công nghiệp đồng nghĩa với việc đối mặt với dữ liệu nhiễu loạn. Rung động, nhiệt độ cao và nhiễu điện từ khiến tín hiệu từ cảm biến không bao giờ “sạch” như lý thuyết.
Các vấn đề thường gặp của Dữ liệu thô (Raw Data):
- Nhiễu (Noise): Dao động ngẫu nhiên làm sai lệch giá trị đo.
- Mất gói tin (Packet Loss): Gián đoạn do đường truyền mạng không ổn định.
- Dữ liệu ngoại lai (Outliers): Các giá trị đột biến vô lý do lỗi phần cứng.
Nạp dữ liệu này trực tiếp vào mô hình AI sẽ dẫn đến kết quả sai lệch theo nguyên lý “Garbage In, Garbage Out” (Rác vào, Rác ra).
Hiện Tượng Trôi Cảm Biến (Sensor Drift)
“Trôi cảm biến” là sự sai lệch âm thầm của giá trị đo theo thời gian do lão hóa vật liệu, nguy hiểm hơn nhiều so với việc hỏng hóc hoàn toàn. Ví dụ, sai số 1% của cảm biến áp suất lò hơi có thể dẫn đến quyết định vận hành vượt ngưỡng an toàn. Tiền xử lý dữ liệu cần tích hợp AI tại biên (Edge AI) để tự động phát hiện độ trôi và hiệu chỉnh (auto-calibration) dựa trên đối chiếu chéo giữa các cảm biến.
Quy Trình Làm Sạch (Cleaning Pipeline)
Để đảm bảo chất lượng dữ liệu đầu vào:
- Lọc nhiễu (Filtering): Dùng thuật toán Moving Average hoặc Low-pass filter.
- Điền khuyết (Imputation): Ước lượng dữ liệu bị mất bằng thống kê hoặc ML.
- Chuẩn hóa (Normalization): Đưa dữ liệu về cùng thang đo để xử lý đồng bộ.
Hợp Nhất Dữ Liệu (Data Fusion) – Chìa Khóa Của Sự Thấu Hiểu
Phá Vỡ “Ốc Đảo Dữ Liệu” (Data Silos)
Dữ liệu doanh nghiệp thường bị phân mảnh: OT (Vận hành), IT (Công nghệ), Lịch sử bảo trì và Dữ liệu tài chính nằm tách biệt. Data Fusion có nhiệm vụ hợp nhất ba dòng chảy:
- Dữ liệu quá khứ: Chuỗi thời gian lịch sử (Time-sequence).
- Dữ liệu hiện tại: Cảm biến thời gian thực (Real-time).
- Dữ liệu tương lai: Dự báo từ mô hình ảo (Simulation).
Công Nghệ Kalman Filter
Trong Data Fusion, Kalman Filter là thuật toán tối quan trọng giúp ước lượng trạng thái hệ thống chính xác ngay cả khi cảm biến bị nhiễu.
- Cơ chế: Liên tục thực hiện vòng lặp Dự đoán (Prediction) dựa trên mô hình vật lý và Cập nhật (Update) dựa trên số liệu đo đạc mới.
- Hiệu quả: Tính toán “trọng số lòng tin” (Kalman Gain) để quyết định nên tin vào mô hình lý thuyết hay cảm biến thực tế tại từng thời điểm, tạo ra một “nguồn sự thật duy nhất” (Single Source of Truth).
Đồng Bộ Hóa Thời Gian (Time Synchronization)
Việc ghép nối dữ liệu rung động (tần suất cao) với dữ liệu bảo trì (tần suất thấp) đòi hỏi kỹ thuật quản lý timestamp và nội suy chính xác, tránh việc liên kết sai nguyên nhân – kết quả trong phân tích sự cố.
Không Gian Ảo & Ứng Dụng AI
Từ Hình Học Đến Hành Vi
Giá trị của Digital Twin không nằm ở hình ảnh 3D, mà ở Mô hình Hành vi (Behavior Models). Ví dụ: Digital Twin của pin xe điện mô phỏng các phản ứng hóa học và nhiệt độ bên trong để dự báo tuổi thọ, điều mà camera hay mắt thường không thể thấy.
Vai Trò Của AI/ML
- Unsupervised Learning: Phát hiện bất thường (Anomaly Detection) chưa từng được định nghĩa.
- Supervised Learning: Dự báo bảo trì (Predictive Maintenance) dựa trên nhãn dữ liệu lịch sử.
- Generative AI: Tạo dữ liệu tổng hợp (Synthetic Data) để huấn luyện mô hình cho các tình huống sự cố hiếm gặp.
Kết luận
Để Digital Twin thực sự trở thành động lực tăng trưởng, doanh nghiệp cần thay đổi tư duy: chuyển sự chú ý từ bề nổi (hình ảnh mô phỏng) sang chiều sâu (chất lượng dữ liệu). Việc làm chủ “Vùng Hỗn Mang” thông qua các chiến lược tiền xử lý và hợp nhất dữ liệu bài bản chính là yếu tố then chốt để đảm bảo dự án thành công và bền vững.





