
Máy học là gì?
Máy học (Machine Learning - ML) là một lĩnh vực trí tuệ nhân tạo (AI) được sử dụng để nhận dạng các mẫu trong tập dữ liệu một cách tự động và trực quan mà không cần được lập trình rõ ràng. Công nghệ này cung cấp khả năng thực hiện dễ dàng hơn các vấn đề phức tạp của thế giới với chi phí tính toán thấp, cũng như đào tạo, xác nhận, kiểm tra và đánh giá nhanh chóng, với hiệu suất cao so với các mô hình vật lý theo cách tương đối ít phức tạp hơn (Mosavi và cộng sự, 2018; Wagenaar và cộng sự. , Năm 2020).
Phân loại các tác vụ máy học
Hầu hết các vấn đề về máy học theo thống kê thuộc một trong hai loại:
Máy học có giám sát
Máy học có giám sát có thể áp dụng những gì đã học trong quá khứ vào dữ liệu mới bằng cách sử dụng các ví dụ được gắn nhãn để dự đoán các sự kiện trong tương lai. Nói cách khác, mục đích là để phù hợp với một mô hình liên quan đến phản ứng với các yếu tố dự đoán và dự đoán chính xác phản ứng cho các quan sát trong tương lai (dự đoán), hoặc hiểu rõ hơn về mối quan hệ giữa phản hồi và các yếu tố dự đoán (suy luận). Bắt đầu từ việc phân tích một tập dữ liệu đào tạo đã biết, thuật toán máy học tạo ra một hàm suy luận để đưa ra dự đoán về các giá trị đầu ra (Casella và cộng sự, 2006). Hệ thống có thể cung cấp các mục tiêu cho bất kỳ đầu vào mới nào sau khi được huấn luyện đầy đủ. Thuật toán máy học cũng có thể so sánh đầu ra của nó với đầu ra chính xác, dự định và tìm ra lỗi để sửa đổi mô hình cho phù hợp. Nhiều phương pháp máy học thống kê cổ điển như hồi quy tuyến tính và hồi quy logic, cũng như các phương pháp tiếp cận hiện đại hơn như máy vectơ tăng cường và hỗ trợ hoạt động trong phạm vi máy học được giám sát. Một thuật toán máy học dựa trên đầu vào được cung cấp hoặc các tính năng tự đào tạo thành (các) hàm có thể được sử dụng thêm để suy ra đầu ra hoặc nhãn. Việc đào tạo được thực hiện với các nhãn chính xác, do đó, thuật toán tự điều chỉnh với việc điều chỉnh các siêu tham số quan trọng nhất trong việc kiểm soát hành vi và dự đoán chính xác. Việc đào tạo dừng lại khi đã đạt được mức hiệu suất có thể chấp nhận được (Liu & Wu, 2012).

Máy học không giám sát
Ngược lại, máy học không giám sát mô tả một tình huống mà đối với mỗi quan sát, có các yếu tố dự báo không có giá trị phản hồi liên quan có thể được sử dụng để giám sát phân tích. Trong cài đặt này, mô hình hoạt động hơi mù mờ vì không có nhãn nào được cấp cho thuật toán máy học, để nó tự tìm cấu trúc trong đầu vào của nó. Máy học không giám sát có thể được sử dụng để khám phá các mẫu ẩn trong dữ liệu và hiểu mối quan hệ giữa các biến hoặc giữa các quan sát. Một công cụ máy học thống kê thường được sử dụng là phân tích cụm (Casella và cộng sự, 2006).
Hạn chế của các phương pháp thông thường
Lũ lụt là một trong những thảm họa thiên nhiên có sức tàn phá nặng nề nhất và chiếm gần một nửa số thảm họa liên quan đến thời tiết, ảnh hưởng đến 2-3 tỷ người. Việc cải thiện khả năng ứng phó nhằm giảm thiểu và quản lý rủi ro lũ lụt có thể được hỗ trợ rất nhiều bởi quan trắc vệ tinh, có thể được sử dụng trong các giai đoạn giảm nhẹ, ứng phó và phục hồi của chu kỳ thiên tai (IPCC, 2012).
Các phương pháp thông thường để lập bản đồ ngập lụt sử dụng các cảm biến vệ tinh quang học và radar ở các độ phân giải không gian và tần số thời gian khác nhau. Các phương pháp tiếp cận như ngưỡng dải, sai lệch chuẩn hóa, kết hợp phức tạp của phổ sóng ngắn hồng ngoại (SWIR) với các dải khác, phát hiện hấp thụ nước dựa trên pixel trong phổ sóng ngắn hồng ngoại được sử dụng để phát hiện, lập bản đồ và giám sát lũ lụt trong hình ảnh quang học. MODIS (Máy quang phổ hình ảnh độ phân giải vừa phải, độ phân giải không gian 250m) khai thác khả năng hấp thụ cao của nước trong SWIR so với các vật thể khác hoặc sử dụng phổ cận hồng ngoại (NIR) so với quang phổ nhìn thấy được. Do đó, cung cấp khả năng phát hiện nước theo nhật ký hàng ngày trên toàn cầu. Các cảm biến có độ phân giải trung bình như Landsat và Sentinel-2 thường được sử dụng để xác định tình trạng ngập lụt bằng cách sử dụng ngưỡng băng tần, sai lệch chuẩn hóa hoặc kết hợp phức tạp hơn của SWIR và NIR với các băng tần khác. Nhược điểm chính của việc sử dụng các kỹ thuật này để phát hiện lũ là chúng bị phân loại sai về nước và bóng mây, cả hai đều có giá trị phản xạ thấp trong SWIR và NIR (Bonafilia và cộng sự, 2020).
Cảm biến SAR (Radar khẩu độ tổng hợp) có thể rất quan trọng trong việc phát hiện lũ lụt do khả năng phát hiện xuyên qua các đám mây của chúng. Các cảm biến SAR như Sentinel-1 đã được sử dụng để lập bản đồ ngập lụt bằng cách xác định nước, thường có giá trị tán xạ ngược thấp hơn so với các đặc điểm khác (trong các dải VV, HH, VH và HV) (Mosavi và cộng sự, 2018). Nước được xác định bằng cách lập ngưỡng các giá trị tán xạ ngược trên một hình ảnh, sự khác biệt về tán xạ ngược giữa hai hình ảnh hoặc phương sai của tán xạ ngược trong một chuỗi thời gian. Thảm thực vật bị ngập và lũ lụt ở các khu vực đô thị có thể làm gia tăng lượng tán xạ ngược trong các trận lũ lụt do hiệu ứng “dội lại kép” (Huang và cộng sự, 2018). Thiệt hại do lũ lụt đô thị đã được ước tính bằng cách sử dụng sự mất liên kết tín hiệu giao thoa kế (thông tin về pha) của các cảm biến SAR giữa hai khoảng thời gian (Rubinato và cộng sự, 2019). Tuy nhiên, gần như tất cả các phương pháp này đều dựa vào ngưỡng để xác định vùng lũ và vùng không lũ. Hơn nữa, các kết quả thu được từ việc xác định ngưỡng thường được đánh giá nguy cơ ngập lụt quá thấp hoặc thấp đối với các khu vực nghiên cứu vì không có hướng dẫn tiêu chuẩn để xác định các giá trị ngưỡng, do người dùng xác định (Bonafilia và cộng sự, 2020).
Các mô hình dựa trên vật lý từ lâu đã được sử dụng để dự đoán các sự kiện thủy văn, chẳng hạn như lượng mưa bão / tình trạng nước nông chảy tràn, các mô hình thủy lực về dòng chảy và các hiện tượng hoàn lưu toàn cầu khác, bao gồm cả các tác động kết hợp của khí quyển, đại dương và lũ lụt. Mặc dù các mô hình vật lý cho thấy những khả năng tuyệt vời để dự đoán nhiều loại kịch bản lũ lụt khác nhau, chúng thường yêu cầu nhiều loại bộ dữ liệu giám sát địa mạo thủy văn khác nhau, do đó đòi hỏi tính toán chuyên sâu, điều này không cho phép dự đoán lũ ngắn hạn. Hơn nữa, việc phát triển các mô hình dựa trên vật lý thường đòi hỏi kiến thức và chuyên môn sâu về các thông số thủy văn và không đáng tin cậy do các sai số hệ thống cố hữu (Mosavi và cộng sự, 2018).
Máy học để phát hiện lũ lụt
Lượng dữ liệu ngày càng tăng, cùng với khả năng tính toán cao hơn và các thuật toán ML tốt hơn để phân tích dữ liệu đang tạo ra những thay đổi trong hầu hết mọi khía cạnh của cuộc sống của chúng ta. Xu hướng này dự kiến sẽ tiếp tục khi có nhiều dữ liệu hơn, khả năng tính toán tăng lên và các thuật toán ML được cải thiện. Đánh giá rủi ro và tác động lũ lụt cũng đang bị ảnh hưởng bởi xu hướng này, đặc biệt trong các lĩnh vực như xây dựng các biện pháp giảm thiểu, chuẩn bị ứng phó khẩn cấp và lập kế hoạch khắc phục hậu quả lũ lụt (Lamovec và cộng sự, 2013; Bonafilia và cộng sự, 2020; Wagenaar và cộng sự ., Năm 2020).
Với tiến bộ tính toán và cải tiến thuật toán, ML đã nổi lên như một công cụ ưa thích để nghiên cứu các hệ thống phi tuyến tính và khám phá các dự đoán được tạo tự động về lũ lụt. Các thuật toán tính toán như mạng nơ-ron chủ yếu được sử dụng để ước tính lũ lụt trong các khu vực bị đe dọa của một con sông và ảnh hưởng của nó bên ngoài khu vực cụ thể. Dự kiến rằng trong tương lai nhiều ứng dụng trở nên khả thi hơn và nhiều quy trình mô hình và phương pháp quan sát truyền thống sẽ được thay thế bằng ML. Ví dụ về điều này bao gồm việc sử dụng ML trên dữ liệu viễn thám để ước tính mức độ phơi nhiễm hoặc trên dữ liệu truyền thông xã hội để cải thiện ứng phó lũ lụt. Một số cải tiến có thể đòi hỏi những nỗ lực thu thập dữ liệu mới, chẳng hạn như để lập mô hình về thiệt hại do lũ lụt hoặc thất bại trong phòng chống (Zehra, 2020).
Dữ liệu lớn để quản lý lũ lụt
Dữ liệu lớn đã phát triển với tốc độ nhanh không thể tin được. Trong bối cảnh cụ thể của khả năng chống chịu với thiên tai, dữ liệu lớn có thể trợ giúp trong cả bốn giai đoạn của quản lý thiên tai: phòng ngừa, chuẩn bị, ứng phó và phục hồi. Sự thúc đẩy dữ liệu mới này kết hợp với các thuật toán máy học có thể dẫn đến những thay đổi trong đánh giá tác động và rủi ro lũ lụt (Wagenaar và cộng sự, 2020). Ngoài ra, dữ liệu lớn cho phép phân tích mô tả (phân tích tình trạng hiện tại hoặc trong quá khứ của lũ lụt), phân tích dự báo (phân tích đánh giá dự báo lũ lụt dài hạn hoặc ngắn hạn), phân tích mô tả và phân tích nhằm giải quyết những khoảng trống trong luồng thông tin trước các tình huống thiên tai, ứng phó thiên tai và khắc phục sau thiên tai (Lamovec và cộng sự, 2013). Dữ liệu từ các công nghệ mới nổi bao gồm hình ảnh vệ tinh, hình ảnh trên không và video từ máy bay không người lái (UAV), web cảm biến và Internet vạn vật (IoT), phát hiện và đo ánh sáng trên không và trên mặt đất (LiDAR), mô phỏng, dữ liệu không gian, nguồn cung ứng cộng đồng, phương tiện truyền thông xã hội, GPS di động và hồ sơ dữ liệu cuộc gọi (CDR) tạo thành cốt lõi của dữ liệu lớn về lũ lụt và các thảm họa khác (Lee et al., 2012).
Những gì hiện đang được hoàn thành?
Để tạo mô hình dự báo ML, các hồ sơ lịch sử của các sự kiện lũ lụt, ngoài dữ liệu tích lũy thời gian thực của một số thiết bị đo mưa hoặc các thiết bị cảm biến khác cho các khoảng thời gian trước khác nhau, thường được sử dụng. Nguồn của bộ dữ liệu theo truyền thống là lượng mưa và mực nước, được đo bằng máy đo mưa trên mặt đất, hoặc các công nghệ viễn thám tương đối mới như vệ tinh, hệ thống cảm biến đa giác quan và / hoặc radar (Seo & Kim, 2016)
Phát hiện và lập bản đồ lũ lụt sử dụng dữ liệu EO
Năm 2011, Veljanovski và cộng sự đã tiến hành so sánh giữa phân định nước dựa trên pixel, phân loại dựa trên đối tượng và quy trình ML. Việc áp dụng quy trình ML để xác định vùng ngập lụt khác với 2 phương pháp khác đã nêu ở trên vì nó sử dụng một bộ dữ liệu phụ trợ rộng rãi hơn. Bên cạnh hình ảnh radar và các dẫn xuất DEM (độ dốc, độ cao), dữ liệu thủy văn (khoảng cách từ các dòng nước) và hiện trạng sử dụng đất cũng được sử dụng để lập mô hình các khu vực ngập lụt. Phương pháp ML tỏ ra thành công trong việc phát hiện lũ lụt dưới ruộng ngô nơi sóng radar không xuyên qua cây trồng xuống vùng đất ngập nước - vị trí mà hai phương pháp còn lại ứng dụng không thành công.
Trong nghiên cứu này, quy trình ML được thực hiện qua các bước sau. Chuẩn bị một bộ dữ liệu mẫu có ý nghĩa: 300 điểm mẫu được tạo ra để đại diện cho khu vực rộng 25 × 20 km. Mỗi điểm trong số này được mô tả bằng sáu thuộc tính: giá trị pixel của hình ảnh radar (cường độ), độ cao, độ dốc, khoảng cách từ nước (sông và suối vĩnh viễn), sử dụng đất và thẻ “ngập lụt” chỉ với hai giá trị được phép: 0 cho vùng không ngập và 1 cho vùng ngập lụt.
Shahabi và cộng sự (năm 2020) đề xuất một kỹ thuật lập bản đồ cảm biến với lũ sử dụng các mô hình tổng hợp dựa trên đóng gói và K-Nearest Neighbor (KNN). Mục đích là để tạo ra các bản đồ có thể được sử dụng bởi nhiều người ra quyết định và quản lý rủi ro để giảm thương tích và thiệt hại cho cơ sở hạ tầng do lũ lụt bằng cách sử dụng dữ liệu radar Sentinel-1 và một số yếu tố điều hòa lũ lụt (độ cao, độ dốc, độ cong, chỉ số dòng chảy, chỉ số độ ẩm địa hình, thạch học, lượng mưa, sử dụng đất / lớp phủ đất, mật độ sông và khoảng cách đến sông). Mô hình hoạt động tốt nhất là mô hình lai ghép thông minh (Bagging Tree – Cubic KNN), là sự kết hợp của kỹ thuật tổng hợp đóng gói và bốn chức năng của bộ phân loại KNN. Tỷ lệ tăng thông tin (IGR) được sử dụng trên mười yếu tố điều hòa lũ lụt và cho thấy rằng, mặc dù tất cả các yếu tố đều có ý nghĩa trong việc đào tạo mô hình, nhưng khoảng cách đến sông nổi bật là yếu tố quan trọng nhất, tiếp theo là độ dốc và độ cong.

Peter và cộng sự, (năm 2013), đã nghiên cứu phát hiện lũ lụt bằng cách sử dụng kỹ thuật ML như một giải pháp thay thế cho các phương pháp thông thường khác để lập bản đồ lũ lụt nhanh chóng. Mặc dù việc đánh giá lũ lụt theo thời gian thực đã được cải thiện đáng kể do tốc độ thu thập dữ liệu tăng lên, độ phân giải cảm biến cao hơn, các thuật toán phát hiện thay đổi được cải tiến và tích hợp hệ thống viễn thám, tuy nhiên, thiên tai sẽ không bao giờ có thể lường trước được hoàn toàn. Trong những tình huống như vậy, các đội cứu hộ cần biết tình hình hiện tại ở hiện trường và thông tin này sẽ được sử dụng tốt nhất nếu khu vực bị ảnh hưởng được lập bản đồ theo thời gian thực. Nghiên cứu kết luận rằng ML đảm bảo việc lập bản đồ nhanh chóng và chính xác. Dữ liệu được sử dụng là ảnh vệ tinh quang học (SPOT 5), mô hình địa hình kỹ thuật số (DTM), mạng lưới sông và đầu ra là mô hình phân loại để phát hiện các khu vực ngập lụt. Các chỉ số khác biệt chuẩn hóa (NDVI, NDBI và NBI) được tính toán bằng cách sử dụng hình ảnh quang học và được đưa vào làm yếu tố dự đoán trong các thuật toán phân loại (Naïve Bayes, Bayes Net, J48, Random Tree và Random Forest). Kết quả đã chứng minh rằng các thuật toán ML có thể được sử dụng để phát hiện các khu vực ngập lụt với độ chính xác cao và chỉ có thể đạt được khi sử dụng cả dữ liệu chất lượng tốt và hiệu quả thuật toán ML.
Dữ liệu để đào tạo mô hình là trở ngại phổ biến nhất đối với việc sử dụng các thuật toán ML để phát hiện lũ lụt. Bonafilia và cộng sự, (2020) đã cố gắng giải quyết trở ngại này bằng cách cung cấp bộ dữ liệu Sen1Floods11. Nghiên cứu nhằm hỗ trợ các nỗ lực vận hành các thuật toán máy học và AI để lập bản đồ lũ lụt trên quy mô toàn cầu. Sen1Floods11 là tập dữ liệu về nước bề mặt bao gồm hình ảnh thô của Sentinel-1 và nước vĩnh viễn và nước lũ được phân loại. Tập dữ liệu này bao gồm 4.831 chip 512x512 có diện tích 120.406 km2 và trải dài trên tất cả 14 quần thể sinh vật, 357 vùng sinh thái và 6 lục địa trên thế giới qua 11 sự kiện lũ lụt. Tập dữ liệu được sử dụng để đào tạo, xác thực và kiểm tra mạng nơ-ron tích tụ đầy đủ (FCNN) để phân đoạn nước vĩnh viễn và ngập lụt. Bộ dữ liệu Sen1Floods11 bao gồm bốn tập con: i) 446 lớp được dán nhãn bằng tay của bề mặt nước từ các sự kiện lũ lụt; ii) 814 nhãn dữ liệu lớp nước vĩnh viễn có sẵn công khai từ Landsat (bộ dữ liệu nước mặt JRC); iii) 4.385 vũng nước mặt được phân loại từ ảnh Sentinel-2 từ các trận lũ và iv) 4.385 vũng nước mặt được phân loại từ ảnh Sentinel-1 từ các trận lũ. Cách tiếp cận này được so sánh với cách tiếp cận viễn thám phổ biến của radar ngưỡng tán xạ ngược để xác định nước trên bề mặt. Kết quả cho thấy mô hình FCNN được đào tạo về phân loại các sự kiện lũ lụt Sentinel-2 hoạt động tốt nhất để xác định lũ và tổng lượng nước bề mặt, trong khi ngưỡng tán xạ ngược mang lại kết quả tốt nhất để chỉ xác định các lớp nước vĩnh viễn. Qua đó gợi ý rằng các mô hình máy học và AI để phát hiện lũ lụt sử dụng dữ liệu radar có thể vượt trội hơn các kỹ thuật viễn thám dựa trên ngưỡng và hoạt động tốt hơn với các nhãn đào tạo bao gồm nước lũ cụ thể, không chỉ nước mặt vĩnh viễn. Có thể tìm thấy mã nguồn của dự án Sen1Floods11 tại:
https://github.com/cloudtostreet/Sen1Floods11
Lập mô hình và dự báo lũ lụt
So với các mô hình thống kê truyền thống, mô hình ML được sử dụng để dự đoán với độ chính xác cao hơn. Ortiz-García và cộng sự. (2014) đã mô tả cách kỹ thuật ML có thể mô hình hóa hiệu quả các hệ thống thủy văn phức tạp như lũ lụt. Nhiều thuật toán ML, ví dụ: mạng nơ-ron nhân tạo (ANN), mờ thần kinh, máy vectơ hỗ trợ (SVM) và hồi quy vectơ hỗ trợ (SVR), đã được báo cáo là hiệu quả cho cả dự báo lũ lụt ngắn hạn và dài hạn. Bên cạnh đó, nó cho thấy rằng hiệu suất của ML có thể được cải thiện thông qua việc lai với các phương pháp ML khác, kỹ thuật tính toán mềm, mô phỏng số / hoặc mô hình vật lý. Các ứng dụng như vậy, cung cấp các mô hình mạnh mẽ và hiệu quả hơn, có thể tìm hiểu các hệ thống lũ phức tạp hiệu quả theo cách thích ứng (Mosavi và cộng sự, 2018).

Các thuật toán máy học phổ biến
Hình 2 mô tả các thuật toán ML được sử dụng nhiều nhất trong tài liệu để phát hiện, dự đoán và lập mô hình lũ lụt theo Mosavi và cộng sự, (2018). Một số thuật toán được mô tả bên dưới.
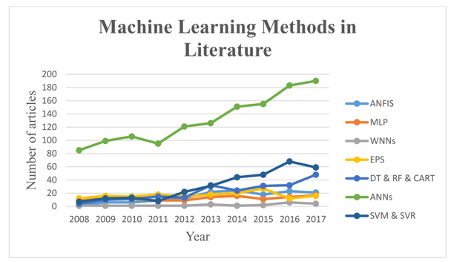
Mạng thần kinh nhân tạo (ANN)
ANN là hệ thống mô hình toán học với quá trình xử lý song song hiệu quả, cho phép chúng bắt chước mạng nơ-ron sinh học bằng cách sử dụng các đơn vị nơ-ron được kết nối với nhau. Trong số tất cả các phương pháp ML, ANN là thuật toán học phổ biến nhất, được biết đến là linh hoạt và hiệu quả trong việc lập mô hình các quá trình lũ phức tạp với khả năng chịu lỗi cao và tính gần đúng chính xác. Do đó, ANN được coi là công cụ định hướng dữ liệu đáng tin cậy để xây dựng các mô hình hộp đen về các mối quan hệ phức tạp và phi tuyến của lượng mưa và lũ lụt, cũng như dự báo dòng chảy và lưu lượng sông. ANN đã được sử dụng thành công cho nhiều ứng dụng dự báo lũ lụt, ví dụ, dự báo dòng chảy, dòng chảy của sông, lượng mưa-dòng chảy, mô hình lượng mưa-dòng chảy, chất lượng nước, bốc hơi, dự đoán giai đoạn sông, ước tính dòng chảy thấp, lập bản đồ lũ và cảm biến với lũ theo chuỗi thời gian của dòng sông. Một nhược điểm lớn khi sử dụng ANN là cần phải lặp lại việc điều chỉnh tham số.
Hệ thống suy luận mờ thần kinh thích ứng (ANFIS)
Logic mờ là một lược đồ mô hình định tính với kỹ thuật tính toán mềm sử dụng ngôn ngữ tự nhiên. Logic mờ là một mô hình toán học đơn giản hóa, hoạt động dựa trên việc kết hợp kiến thức chuyên môn vào một hệ thống suy luận mờ (FIS). ANFIS tiếp tục mô phỏng quá trình học tập của con người thông qua một hàm gần đúng ít phức tạp hơn, mang lại tiềm năng lớn cho việc lập mô hình phi tuyến tính về các hiện tượng thủy văn khắc nghiệt, đặc biệt là lũ lụt. Do thực hiện nhanh chóng và dễ dàng, học chính xác và khả năng tổng quát hóa mạnh mẽ, ANFIS trở nên rất phổ biến trong mô hình lũ lụt.
Cây quyết định (DT)
DT là một trong những phương pháp trong việc lập mô hình dự báo với ứng dụng rộng rãi trong mô phỏng lũ lụt. DT sử dụng cây quyết định từ cành đến giá trị đích của lá. Trong cây phân loại (CT), các biến cuối cùng trong DT chứa một tập hợp các giá trị rời rạc, trong đó các lá biểu thị nhãn lớp và các nhánh biểu thị các liên kết của nhãn đối tượng. Khi biến mục tiêu trong DT có các giá trị liên tục và một nhóm cây có liên quan, nó được gọi là cây hồi quy (RT). Cây hồi quy và cây phân loại có một số điểm giống và khác nhau. Do DT được phân loại là các thuật toán nhanh, chúng trở nên rất phổ biến ở dạng tập hợp để lập mô hình và dự đoán lũ lụt. Phương pháp rừng ngẫu nhiên (RF) là một phương pháp DT phổ biến khác để dự báo lũ. RF bao gồm một số bộ dự báo cây. Mỗi cây tạo ra một tập hợp các giá trị dự đoán phản hồi được liên kết với một tập hợp các giá trị độc lập. Hơn nữa, một quần thể của những cây này chọn ra sự lựa chọn tốt nhất của các lớp.
Hệ thống dự đoán tổng hợp (EPS)
Các tổ hợp ML bao gồm một tập hợp hữu hạn các mô hình thay thế, thường cho phép linh hoạt hơn các mô hình thay thế. Trong những năm gần đây, các hệ thống dự báo tổng hợp (EPS) đã được đề xuất như một hệ thống dự báo hiệu quả để cung cấp một nhóm N dự báo. Trong EPS, N là số lần thực hiện độc lập của phân phối xác suất mô hình.
Các mô hình EPS thường sử dụng nhiều thuật toán ML để cung cấp hiệu suất cao hơn bằng cách sử dụng hệ thống đánh giá và trọng số tự động. Quy trình trọng số như vậy được thực hiện để đẩy nhanh quá trình đánh giá hiệu suất. Ưu điểm của EPS là quản lý và đánh giá hiệu suất kịp thời và tự động của các thuật toán tổng hợp. Do đó, hiệu suất của EPS, đối với mô hình lũ lụt, có thể được cải thiện. Các EPS có thể sử dụng nhiều thuật toán thống kê dưới dạng tập hợp bộ phân loại, ví dụ: ANN, MLP, DT, bootstrap rừng xoay vòng (RF) cho phép độ chính xác và khả năng dự báo mạnh mẽ hơn.
Các hệ thống dự báo tổng hợp tiếp theo có thể được sử dụng để định lượng xác suất lũ lụt, dựa trên tỷ lệ dự đoán được sử dụng trong trường hợp này. Do đó, chất lượng của các tổ hợp ML có thể được tính toán dựa trên việc xác minh phân phối xác suất.
Hỗ trợ máy vectơ (SVM)
SVM rất phổ biến trong mô hình lũ lụt; nó là một máy học có giám sát hoạt động dựa trên lý thuyết học thống kê và quy tắc giảm thiểu rủi ro cấu trúc. Thuật toán đào tạo của SVM xây dựng các mô hình chỉ định bộ phân loại tuyến tính nhị phân không xác suất mới, giúp giảm thiểu lỗi phân loại theo kinh nghiệm và tối đa hóa biên hình học thông qua giải quyết vấn đề ngược. SVM được sử dụng để dự đoán một lượng chuyển tiếp trong thời gian dựa trên việc đào tạo từ dữ liệu trong quá khứ. SVM ngày nay được gọi là thuật toán ML mạnh mẽ và hiệu quả để dự đoán lũ lụt. SVM và SVR nổi lên như là các phương pháp ML thay thế cho ANN, được các nhà thủy văn học ưa chuộng để dự báo lũ. Do đó, chúng được áp dụng trong nhiều trường hợp dự báo lũ với kết quả đầy hứa hẹn, khả năng tổng quát hóa tuyệt vời và hiệu suất tốt hơn, so với ANN, ví dụ: lượng mưa, lượng mưa cực đoan,lượng mưa-dòng chảy, dòng chảy của hồ chứa, dòng chảy, lượng tử lũ, chuỗi thời gian lũ, và độ ẩm của đất.
Ưu điểm
Các mô hình ML ngày càng được sử dụng rộng rãi để dự đoán, lập bản đồ và giám sát các sự kiện lũ lụt, mang lại hiệu suất tốt hơn và các giải pháp hiệu quả về chi phí. Việc phát triển các mô hình dự báo lũ là cần thiết để giảm thiểu rủi ro, đề xuất chính sách, giảm thiểu thiệt hại về người, lập bản đồ lũ nhanh và giảm thiệt hại về tài sản do lũ lụt. Dự báo lũ lụt bằng cách sử dụng các thuật toán máy học đạt hiệu quả do khả năng sử dụng dữ liệu từ nhiều nguồn khác nhau, phân loại, hồi quy nó thành các lớp lũ và không lũ.
Những hạn chế của các mô hình thống kê và dựa trên vật lý được đề cập ở trên khuyến khích việc sử dụng các mô hình hướng dữ liệu nâng cao như ML. Các phương pháp dự báo dựa trên dữ liệu đồng hóa các chỉ số khí hậu đo được và các thông số khí tượng thủy văn để cung cấp cái nhìn sâu sắc hơn. Nhiều thuật toán ML, ví dụ, mạng nơ-ron nhân tạo (ANN), logic mờ, máy hỗ trợ vectơ (SVM) và hỗ trợ hồi quy vectơ (SVR), đã được báo cáo là hiệu quả cho cả dự báo lũ lụt ngắn hạn và dài hạn (Mosavi và cộng sự, 2018).
Một lý do nữa cho sự phổ biến của các mô hình ML là chúng có thể hình thành tính phi tuyến tính về mặt số học, chỉ dựa trên dữ liệu lịch sử mà không yêu cầu kiến thức về các quá trình vật lý cơ bản. Các mô hình dự đoán theo hướng dữ liệu sử dụng ML là công cụ đầy hứa hẹn vì chúng được phát triển nhanh hơn với đầu vào tối thiểu.
Trong dự báo lũ lụt, các phương pháp dự báo các biến nguy cơ truyền thống có thể liên quan đến một chuỗi các mô hình thủy văn và thủy lực mô tả các quá trình vật lý. Mặc dù các mô hình như vậy cung cấp sự hiểu biết về hệ thống, chúng thường có các yêu cầu tính toán và dữ liệu cao. Do đó, việc sử dụng các mô hình quy trình có thể không phải lúc nào cũng khả thi hoặc cần thiết trong giai đoạn chuẩn bị cho một thảm họa. Phương pháp ML có tiềm năng cải thiện độ chính xác cũng như giảm thời gian tính toán và chi phí phát triển mô hình. Tại thời điểm đó, kết quả đầu ra chính xác và kịp thời trở nên quan trọng hơn sự hiểu biết hệ thống và việc sử dụng các mô hình ML ‘hộp đen’ ngày càng trở nên phổ biến (Wagenaar và cộng sự, 2020)
Hạn chế
Mặc dù các thuật toán ML có nhiều ưu điểm, nhưng chúng có những đặc điểm quan trọng thường là những hạn chế.
Đầu tiên là chúng tốt như quá trình đào tạo của chúng, theo đó hệ thống tìm hiểu mục tiêu dựa trên dữ liệu trong quá khứ. Nếu dữ liệu khan hiếm hoặc không bao gồm các loại mục tiêu, việc đào tạo của chúng sẽ bị thiếu hụt và do đó, các thuật toán này không thể thực hiện tốt khi được đưa vào làm việc. Như vậy, việc sử dụng một tập dữ liệu đào tạo mạnh mẽ là điều cần thiết.
Thứ hai, khả năng của mỗi thuật toán ML, có thể khác nhau đối với các loại nhiệm vụ khác nhau. Đây cũng có thể được gọi là “bài toán tổng quát hóa”, cho biết hệ thống được đào tạo có thể dự báo các trường hợp mà nó không được đào tạo tốt như thế nào, tức là liệu nó có thể dự báo ngoài phạm vi của tập dữ liệu đào tạo hay không. Ví dụ: một số thuật toán có thể hoạt động tốt đối với các dự báo ngắn hạn, nhưng không hoạt động tốt đối với các dự báo dài hạn. Các đặc điểm này của các thuật toán cần được làm rõ liên quan đến loại và số lượng dữ liệu đào tạo có sẵn cũng như loại nhiệm vụ dự báo.
Nhiệm vụ chọn thuật toán ML hoạt động tốt nhất có thể khó khăn do độ phức tạp của dữ liệu và thường yêu cầu phương pháp thử-và-sai đối với các tham số điều chỉnh. Độ chính xác của thuật toán ML được sử dụng phụ thuộc rất nhiều vào các tham số điều chỉnh và các giá trị tham số điều chỉnh tốt nhất không phải là tĩnh đối với mọi tập dữ liệu.
Tài liệu tham khảo
- Bonafilia, D., Tellman, B., Anderson, T., & Issenberg, E. (2020). Sen1Floods11: A georeferenced dataset to train and test deep learning flood algorithms for sentinel-1. IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2020-June, 835–845. https://doi.org/10.1109/CVPRW50498.2020.00113
- Casella, G., Fienberg, S., & Olkin, I. (2006). An Introduction to Statistical Learning. In Design (Vol. 102). https://doi.org/10.1016/j.peva.2007.06.006
- Huang, C., Chen, Y., Zhang, S., & Wu, J. (2018). Detecting, Extracting, and Monitoring Surface Water From Space Using Optical Sensors: A Review. Reviews of Geophysics, 56(2), 333–360. https://doi.org/10.1029/2018RG000598
- IPCC. (2012). Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation. In Special Report of the Intergovernmental Panel on Climate Change (Vol. 9781107025). https://doi.org/10.1017/CBO9781139177245.009
- Lamovec, P., Veljanovski, T., Mikoš, M., & Oštir, K. (2013). Detecting flooded areas with machine learning techniques: case study of the Selška Sora river flash flood in September 2007. Journal of Applied Remote Sensing, 7(1), 073564. https://doi.org/10.1117/1.jrs.7.073564
- Lee, S., Hahn, C., Rhee, M., Oh, J. E., Song, J., Chen, Y., Lu, G., Perdana, & Fallis, A. . (2012). E-Agriculture in Action: Big Data for Agriculture. In Journal of Chemical Information and Modeling (Vol. 53, Issue 9). http://dx.doi.org/10.1016/j.tws.2012.02.007
- Liu, Q., & Wu, Y. (2012). Supervised Learning. Encyclopedia of the Sciences of Learning, January 2012. https://doi.org/10.1007/978-1-4419-1428-6
- Mosavi, A., Ozturk, P., & Chau, K. W. (2018). Flood prediction using machine learning models: Literature review. Water (Switzerland), 10(11). https://doi.org/10.3390/w10111536
- Peter, L., Matjaž, M., & Krištof, O. (2013). Detection of Flooded Areas using Machine Learning Techniques : Case Study of the Ljubljana Moor Floods in 2010. June 2014.
- Rubinato, M., Nichols, A., Peng, Y., Zhang, J. min, Lashford, C., Cai, Y. peng, Lin, P. zhi, & Tait, S. (2019). Urban and river flooding: Comparison of flood risk management approaches in the UK and China and an assessment of future knowledge needs. Water Science and Engineering, 12(4), 274–283. https://doi.org/10.1016/j.wse.2019.12.004
- Seo, Y., & Kim, S. (2016). River Stage Forecasting Using Wavelet Packet Decomposition and Data-driven Models. Procedia Engineering, 154, 1225–1230. https://doi.org/10.1016/j.proeng.2016.07.439
- Shahabi, H., Shirzadi, A., Ghaderi, K., Omidvar, E., Al-Ansari, N., Clague, J. J., Geertsema, M., Khosravi, K., Amini, A., Bahrami, S., Rahmati, O., Habibi, K., Mohammadi, A., Nguyen, H., Melesse, A. M., Ahmad, B. Bin, & Ahmad, A. (2020). Flood detection and susceptibility mapping using Sentinel-1 remote sensing data and a machine learning approach: Hybrid intelligence of bagging ensemble based on K-Nearest Neighbor classifier. Remote Sensing, 12(2). https://doi.org/10.3390/rs12020266
- Veljanovski, T., Lamovec, P., Pehani, P., & Oštir, K. (2011). Comparison of three techniques for detection of flooded areas on ENVISAT and RADARSAT-2 satellite images. Gi4DM 2011 - GeoInformation for Disaster Management.
- Wagenaar, D., Curran, A., Balbi, M., Bhardwaj, A., Soden, R., Hartato, E., Mestav Sarica, G., Ruangpan, L., Molinario, G., & Lallemant, D. (2020). Invited perspectives: How machine learning will change flood risk and impact assessment. Natural Hazards and Earth System Sciences, 20(4), 1149–1161. https://doi.org/10.5194/nhess-20-1149-2020
- Zehra, N. (2020). Prediction Analysis of Floods Using Machine Learning Algorithms ( NARX & SVM ). International Journal of Sciences: Basic and Applied Research (IJSBAR), 4531, 24–34.
Bài liên quan
: Những Xu hướng Mới và Dự báo Tương lai 1")
Quản lý tài sản doanh nghiệp (EAM): Những Xu hướng Mới và Dự báo Tương lai

Chuyển đổi số trong công nghiệp dầu khí: 6 phương pháp nâng cao hiệu quả quản lý


 của HxGN EAM 5")

 - GIẢI PHÁP OPCENTER EXECUTION DISCRETE GIÚP TỐI ƯU HIỆU QUẢ SẢN XUẤT TRONG GIAI ĐOẠN CHUYỂN ĐỔI SỐ 7")

 - Opcenter RD&L, thúc đẩy hiệu quả đổi mới trong thiết kế sản phẩm 9")




 – Internet vạn vật trong đời sống và doanh nghiệp 14")

